
07 Oct Se tromper n’est pas toujours mauvais : les erreurs des protéines sont sous contrôle
Cartographier où ces erreurs se produisent est un tour de force qui semblait impossible. Beaucoup de ces erreurs ne se produisent pas aléatoirement.
Déterminer où et quand ont lieu les erreurs dans la fabrique de protéines cellulaire est un tel défi qu’un chercheur américain a déclaré offrir un an de déjeuner à qui percerait ce mystère. Le professeur Yitzhak Pilpel, directeur du département de Génétique Moléculaire de l’Institut Weizmann des Sciences, n’a pas pu bénéficier de cette offre, à cause de la distance, mais suite à une de ses études, récemment publiée dans Molecular Cell, il s’est empressé d’écrire un mail à son homologue américain : mission impossible réalisée !
Le professeur Pilpel et d’autres scientifiques israéliens et européens ont non seulement réussi à mesurer le taux d’apparition d’erreurs quand les protéines sont créées dans les cellules, mais ont aussi révélé que l’ADN contient une sorte de guide des erreurs qui décrit quand ces erreurs doivent être évitées à tout prix et quand elles peuvent être tolérées voire souhaitables. Certaines erreurs peuvent ainsi entraîner l’accumulation de protéines anormales dans une cellule, comme cela arrive dans le cas de la maladie d’Alzheimer, tandis que d’autres peuvent donner à une cellule un avantage évolutif.
Les erreurs dans la production de protéines peuvent trouver leur origine dans des fautes de syntaxe au sein même de l’ADN, mais en général, elles se produisent plus tard dans le processus de production, quand le message génétique est copié et envoyé au ribosome, la fabrique de protéines de la cellule. Jusqu’à présent, cartographier ces erreurs, qui apparaissent tardivement, était presque impossible car toutes les analyses donnaient un taux moyen d’erreurs pour l’ensemble des briques qui constituent les protéines – les acides aminés – dans une cellule, cecii signalait la présence d’erreurs mais ne permettait pas de les situer dans les protéines.
 (de gauche à droite) Le professeur Yotzhak Pilpel, le docteur Orna Dahan, Omer Asraf et le docteur Roni Rak
(de gauche à droite) Le professeur Yotzhak Pilpel, le docteur Orna Dahan, Omer Asraf et le docteur Roni Rak
Le professeur Pilpel, en collaboration avec le professeur Tamar Geiger de l’Université de Tel Aviv et le professeur Ariel B. Lindner de l’Université Paris Descartes, a accompli ce défi en appliquant des algorithmes avancés sur les données obtenues avec un spectromètre de masse, selon une méthode spécialement élaborée pour étudier les substitutions individuelles des acides aminés dans une protéine. Les chercheurs ont ensuite testé cette approche sur des cellules de levures et de bactéries à division rapide et ont réussi à détecter, quantifier et analyser toutes les erreurs dans les protéines des cellules, en remontant jusqu’à la composition de chaque acide aminé. Cette étude a été conduite par Ernest Mordret, étudiant diplômé du professeur Pilpel. L’équipe de recherche comprenait également le docteur Orna Dahan, Omer Asraf et Avia Yehonadav du Département de Génétique Moléculaire ; le docteur Georgina D. Barnabas de l’Université de Tel Aviv ; et le professeur Jürgen Cox de l’Institut Max Planck de Biochimie.
Il s’est avéré que les erreurs se produisent plus généralement dans le ribosome – soit au stade final de la production des protéines appelé “translation”. À cette étape, les mauvais acides aminés sont insérés dans une protéine en proportion d’un pour mille – soit environ une erreur par protéine. Mais l’écart type est important : il va d’une erreur pour quelques dizaines d’acides aminés jusqu’à une erreur pour dix mille acides aminés.
Les erreurs sont “autorisées” là où elles sont le moins nuisibles
La découverte la plus surprenante a peut-être été que la distribution de ces erreurs est bien loin d’être aléatoire. Dans les cellules, les protéines erronées sont beaucoup plus fréquentes en petite quantité. Ceci est probablement dû au fait que si une cellule contient trop de protéines erronées, elle ne survivra pas au cours de l’évolution. De plus, au sein de chaque protéine, les erreurs de traduction sont plus communes dans les parties les moins critiques, gérant la fonction et la stabilité protéique, plutôt que dans les parties plus cruciales – par exemple, les sites responsables de la liaison aux autres molécules.
“Nous avons découvert que les erreurs sont “autorisées” là où elles sont le moins nuisibles mais pas au niveau des sites sensibles,” dit le professeur Pilpel.
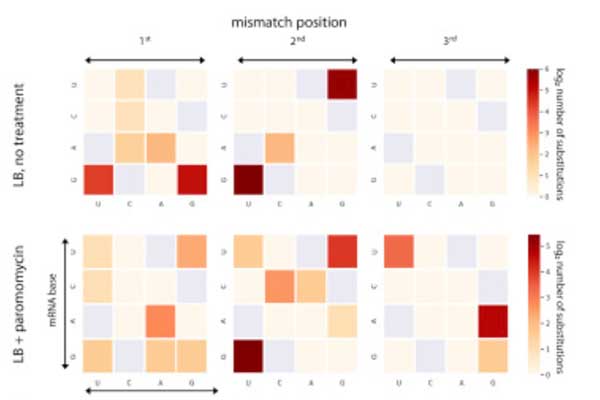
Une petite dose d’antibiotiques (en bas) entraîne la production d’un plus grand nombre d’erreurs, en particulier pour certaines localisations. Plus la couleur est sombre, plus le nombre de substitutions est élevé.
Mais comment le ribosome sait-il quand lil est “autorisé” à faire des erreurs ? Les résultats de l’étude suggèrent que le taux d’erreurs à cette étape est au moins partiellement préprogrammé et que cette préprogrammation pourrait trouver sa source dans la régulation de la vitesse de traduction. En fait, les scientifiques ont découvert une corrélation inverse entre la vitesse de traduction et la justesse. Plus la vitesse de synthèse des protéines par le ribosome est élevée, plus il y a d’erreurs. Et inversement, le ribosome est apparemment programmé pour ralentir quand il travaille sur des protéines essentielles à la cellule, comme s’il prenait son temps pour faire les choses correctement. La vitesse de traduction, peut, quant à elle, être contrôlée via un mécanisme génétique révélé dans une étude précédente du professeur Pilpel. Ce mécanisme a un lien avec le fait que le même acide aminé peut être encodé par différentes séquences de trois lettres. Le professeur Pilpel et son équipe ont montré que certaines de ces séquences – celles qui emploient un grand nombre de molécules support – permettent au ribosome de gagner en vitesse, tandis que d’autres utilisent un nombre réduit de molécules, forçant le ribosome à ralentir jusqu’à ce qu’il obtienne finalement la molécule requise.
Dans cette nouvelle étude, les chercheurs ont aussi découvert que les erreurs de traduction peuvent être déclenchées par des conditions extérieures. Quand ils ont exposé des cellules en division à des antibiotiques, le taux d’erreur a augmenté.
Ces découvertes ouvrent une nouvelle voie de recherche. Des études plus approfondies pourraient par exemple examiner le rôle des erreurs de traduction dans la maladie d’Alzheimer ou d’autres maladies dégénératives. D’autres études pourraient déterminer si ces erreurs ralentissent ou accélèrent la croissance des cellules cancéreuses ou si elles accélèrent le processus de vieillissement.
Cette nouvelle découverte pourrait aussi aider à établir le rôle des erreurs de traduction dans l’évolution des espèces en créant diverses protéines pouvant aider les organismes à s’adapter aux changements de conditions. « Les erreurs dans les protéines créent de la diversité au sein de cellules génétiquement identiques – une diversité qui peut se révéler bénéfique dans la course à l’évolution, » dit le professeur Pilpel.
Les recherches du professeur Yitzhak Pilpel sont financées par le Centre de la Famille David et Fela Shapell pour la Recherche sur les Maladies Génétiques ; l’Institut Azrieli pour la Biologie des Systèmes ; le Centre Leo et Julia Forchheimer pour la Génétique Moléculaire ; le Laboratoire Sharon Zuckerman pour la recherche sur la Biologie des Systèmes ; la succession Emile Mimran ; et le Centre européen pour la Recherche. Le professeur Pilpel est détenteur de la chaire professorale Ben May.